

使用恰好有一个轻子(e或\(\mu \))、至少四个喷流(包括至少一个b标记喷流)和大量缺失横向动量的事件来搜索成对产生的类矢量夸克。本文分析了2015年至2018年LHC的ATLAS探测器记录的质心能量为\(\sqrt{s}=\)13 \( ext {TeV}\)的质子-质子碰撞数据,这些数据对应的综合光度为139 fb\(^{-1}\)。考虑了顶夸克和底夸克的类矢量伙伴T和B,以及电荷为\(+5/3\)的类矢量X,假设它们衰变为W、Z或希格斯玻色子和第三代夸克。没有观察到与标准模型期望的显著偏差。在不同的衰变分支比情况下,推导了T和B夸克对的产生截面随质量变化的上限。假设质量简并的类矢量夸克和分支比对应于弱同位旋双重态模型,质量的最强下限为1.59 \( ext {TeV}\),对于排他的\(T \rightarrow Zt\) (\(B/X \rightarrow Wt\))衰变为1.47 \( ext {TeV}\) (1.46 \( ext {TeV}\))。此外,对于所有可能的分支比,我们推导出了T和B夸克质量的下限。
粒子物理学中的微调或自然性问题[1]是由二次发散的希格斯玻色子质量的环修正引起的。如果标准模型是完整的,这些将导致对普朗克尺度量级的希格斯质量的修正,并且需要一个精细调整的类似值的裸希格斯质量来达到大约125的测量质量[2]。
类矢量夸克(VLQs)[3,4,5,6]可以通过显著地促进环修正来抑制对希格斯玻色子质量的非自然大的二次修正。它们是假设的自旋为1/2的有色粒子,其左手态和右手态具有相同的电弱耦合。它们出现在粒子物理学标准模型(SM)之外的许多理论中,主要是在“小希格斯”[7,8,9]和“复合希格斯”[10,11]类模型中。
在大型强子对撞机(LHC)中,VLQs可以通过电弱相互作用单独产生,也可以通过强相互作用成对产生。后者的横截面仅取决于VLQ的质量,而前者则额外依赖于电弱玻色子与VLQ之间未知的耦合强度。vlq预计将优先与第三代夸克耦合[3,12]。因此,上型带电荷VLQ T如下所示,假设只有三种可能的衰变模式,和。同样,带电荷的下型VLQ B也可以衰变成Zb、Hb或Wt。带电荷的类矢量X夸克也出现在带T伴子的多重态中[4,13],并且只通过衰变。
图1
a和b产生和衰变的代表性费曼图。在分析中,没有对粒子和反粒子进行区分,导致对最终状态也很敏感
该分析研究了成对产生的类矢量T (VLT)夸克和B (VLB)夸克的所有可能的衰变模式和分支比组合,如图1所示。然而,它是最敏感的和衰变。由于分析没有区分粒子和反粒子,所以极限也适用于类矢量X夸克,因为它只会衰变为Wt。分支比率的特定组合对应于弱同位旋单线态和双线态模型。对于T夸克和B夸克,每种衰变模式的分支比取决于VLQ质量和弱同位旋量子数[4]。下面给出的分支比适用于800gev以上的VLQ质量,它们与VLQ质量基本无关。对于单重态T,所有的衰变模式都有相当大的分支比(),而如果T在(X, T)重态或(T, B)重态中,只要满足广义Cabibbo-Kobayashi-Maskawa (CKM)矩阵元素,它就只能衰变为分支比相等的Zt或Ht[4]。同样,对于单重态B,所有衰变模式的分支比都是相当大的(),而对于具有衰变的(T, B)双重态场景是唯一的可能性。
结果基于ATLAS实验收集的完整Run 2(2015-2018)数据集,该数据集在大型强子对撞机上进行了13 TeV质子-质子碰撞,对应的综合光度为139 fb。ATLAS[14,15,16,17,18,19,20,21]和CMS[22,23,24,25]已经对针对不同最终状态的成对产生的vlq进行了多次搜索。这些结果是基于Run 2数据的一个子集,大约36fb,除了Refs。(21,25)。使用36fb数据集的ATLAS结果组合也可用[26],不包括T (B)质量低于1.31(1.03)的任何组合,用于上述讨论的每VLQ的三种衰变模式。
分析是基于一个最终状态特征,具有高缺失的横向动量,一个轻子(e或),以及至少四个喷气机,包括一个b标记喷气机。在这个最终状态下,之前的ATLAS搜索是基于Run 2数据的一个子集[16],在单重态(双重态)模型中,T夸克质量的下限为1.16 %,T夸克质量的下限为0.87(1.05)。这里的分析主要是通过研究类矢量B夸克和使用经过几个分支比训练的神经网络(nn)来将信号从背景中分离出来,而不是使用单个信号区域(SR)的切割计数分析来扩展的。T和B分别在一个共同的训练区域中使用模拟事件进行训练。每个SRs都是由训练区域的一个子集通过对相应NN输出的选择来定义的。控制区域(cr)被定义,以便在各种背景过程中得到丰富。它们与训练区域正交,因此与SRs正交,并且彼此正交。统计解释是基于对T或B的cr和SR的同时拟合,其中确定了+喷流和单顶夸克背景的归一化和可能的信号贡献。
表1针对信号和不同背景进程的ME发生器、PDF集、PS模型和调谐列表
全尺寸工作台
大型强子对撞机的ATLAS实验[27]是一种多用途的粒子探测器,具有前后对称的圆柱形几何结构和近立体角覆盖。它由一个内部跟踪探测器(ID)组成,被一个提供2T轴向磁场的薄超导螺线管包围,电磁和强子量热计,以及一个μ子光谱仪。内部跟踪检测器覆盖伪快度范围。它由硅像素、硅微带和跃迁辐射跟踪探测器组成。铅/液氩(LAr)取样量热计提供高粒度的电磁(EM)能量测量。钢/闪烁体-瓦强子量热计覆盖中心伪快度范围()。末端和前方区域用LAr量热计进行电磁和强子能量测量,测量范围可达。介子光谱仪围绕着量热计,并基于三个大型超导空芯环形磁体,每个磁体有八个线圈。环面在探测器大部分区域的场积分在2.0 ~ 6.0 T m之间。μ子光谱仪包括一个精确跟踪室系统和用于触发的快速探测器。采用两级触发系统选择事件。第一级触发器在硬件中实现,并使用检测器信息的子集以低于100 kHz的速率接受事件。然后是基于软件的高级触发器(HLT),根据数据采集条件将可接受的事件速率平均降低到1 kHz。在数据模拟、真实和模拟数据的重建和分析、探测器操作以及实验的触发和数据采集系统中使用了广泛的软件套件[28]。
该分析使用了2015年至2018年LHC上的ATLAS探测器记录的质子-质子(pp)碰撞数据。该数据集是在稳定光束条件下收集的,所有探测器子系统都在运行[29],对应的综合光度为139 fb,不确定度为1.7%[30]。在大型强子对撞机达到的高光度下,在相同或邻近的束交叉中,事件受到额外的非弹性pp碰撞的影响,称为堆积。每束交叉的平均相互作用数为33.7。触发器在数据采集过程中在线选择事件[31],2015年HLT的阈值为70,之后几年的阈值从90上升到110。
利用蒙特卡罗(MC)模拟事件对背景过程和VLQ信号进行建模。表1总结了模拟标称样本的详细信息,包括矩阵元素(ME)发生器和部分分布函数(PDF)集,部分淋浴(PS)和强子化模型,以及调谐参数集(tune)。
生成的事件通过使用Geant4[33]模拟ATLAS探测器的几何形状和响应来处理[32]。在某些情况下,采用量热计响应参数化的更快的模拟用于估计系统的不确定性。在这些情况下,将系统变化的样本与也通过快速模拟处理的标称样本的版本进行比较。为了模拟堆积效应,使用调优参数集A3[35]与Pythia 8.186[34]生成最小偏差pp相互作用,并叠加在模拟的硬散射事件上。对结果事件进行加权,以匹配记录数据的堆积概况。
最后,使用与碰撞数据相同的软件对模拟事件进行重构。对模拟事件进行校正,以使目标识别效率、能量尺度和分辨率与辅助测量数据确定的目标识别效率、能量尺度和分辨率相匹配。
利用NNPDF 2.3lo PDF[37]集,利用Protos v2.2[36]以导阶(LO)生成了类矢量T和B夸克成对产生的信号样本,并与Pythia 8.186接口,模拟了部分子雨、强子化和潜在事件。使用窄宽度近似,样品的质量从800到2,质量间距从1到1.8为100。vlq的手性依赖耦合被设置为弱同位旋单重态模型中的耦合,但对于类矢量T夸克具有相同的分支比例,分为三种衰变模式(Zt, Ht, Wb)和类矢量B夸克具有相同的分支比例(Zb, Hb, Wt)。为了测试假设的单线态耦合的潜在运动学偏差,在双线态模型中为1.2质量点生成了专用信号样本。对于T夸克,这个选择是保守的,因为在双重态情况下接受度更高,而对于B夸克,单重态和双重态耦合的接受度相似。为了获得所需的分支比率,执行基于生成器信息的逐个事件重加权。使用top++ 2.0[38]计算QCD中次至次至次阶(NNLO)下的信号样本截面,包括恢复次至次至次对数(NNLL)软胶子项。
事件的产生使用Powheg Box v2[39,40,41,42]生成器进行建模,顺序为(),pdf的NNPDF 3.0nlo集[43],参数footnote 2设置为[44],其中。这些事件被连接到皮媞亚8.230。在包括用top++ 2.0计算的软胶子项时,将截面修正为理论预测。
使用Powheg Box v2发生器在QCD中使用NNPDF 3.0nlo pdf集生成单顶夸克事件样本,其中tW和s通道单顶事件的五种风味方案和t通道单顶事件的四种风味方案。tW样品使用图去除方案[45]建模,以消除与生产的干扰和重叠。事件与Pythia 8.230或Pythia 8.235交互。将样品归一化为其QCD横截面[46,47],并添加了用于生产tW的软胶子项[48,49]。
使用Sherpa 2.2.1生成器模拟+jets()的生成,使用最多两个部分的-精确矩阵元素和最多四个部分的LO矩阵元素,使用Comix[50]和OpenLoops[51,52,53]库进行计算。使用MEPS@NLO处方[55,56,57,58]和Sherpaauthors开发的一组调优参数,将它们与SherpaPS[54]进行匹配。使用NNPDF 3.0nnlo pdf集,并将样本归一化为预测[59]。
用夏尔巴2.2.1或2.2.2生成器模拟二玻色子终态(VV)的样本,这取决于过程,包括脱壳效应和适当的希格斯玻色子贡献。完全轻子最终态和半轻子最终态,其中一个玻色子轻子衰变,另一个强子衰变,在QCD中使用矩阵元素以精确的方式产生,最多可增加一个部分子,最多可增加三个部分子发射。矩阵元素与PS的匹配和不同喷流多样性的合并采用与+喷流生产相同的方法。使用了NNPDF 3.0nnlo pdf集,以及sherpa内部调。将二色子事件样本归一化为QCD中Sherpaat计算的总截面。
和事件的产生使用MadGraph5_aMC@NLO 2.3.3[60]生成器和NNPDF 3.0nlo PDF集进行建模。这些事件被连接到Pythia 8.210。类似地,使用MadGraph5_aMC@NLO 2.6.8 at和NNPDF 3.0nlo PDF集(与Pythia 8.244接口)对事件的生成进行建模。采用消图方案处理和之间的干扰,并应用于样品。事件生成的示例是使用Powheg Box v2生成器和NNPDF 3.0nlo PDF集生成的,与Pythia 8.230接口。生成的样本,,,和生产归一化到通过MadGraph5_aMC@NLO计算的截面预测。
除了使用Sherpa[61]事件生成器生成的样品外,所有模拟样品都使用EvtGen[62]程序来模拟重味强子的衰变。VLQ信号采样和采样使用EvtGen 1.2.0,其他均使用EvtGen 1.6.0。对于使用Pythia 8[63]进行淋浴和hadronisation的所有标称样本,Pythia与A14[64]调优参数集和NNPDF 2.3lo pdf集一起使用。
事件必须至少有一个pp碰撞顶点候选点,并且至少有两个具有横向动量的相关轨迹。主顶点被定义为所有相关轨迹横向动量标量和最大的候选顶点。在这个分析中,电子、介子和喷流是使用的校准物理对象。对于带电轻子,施加了两组质量和运动学要求,其中信号轻子的选择比基线轻子更严格。
从与ID中带电粒子轨迹匹配的EM量热计中的能量沉积重建候选电子。基线电子需要具有并在其中重建,不包括桶端帽过渡区域。它们必须满足“松散”的识别标准,使用基于似然的鉴别器,结合ID中的轨迹信息和量热计系统中的能量沉积[65],并且需要在像素探测器的最内层有命中。此外,量热计和内径都有隔离要求[65]。如果在减去堆积和电子本身的贡献后,在周围半径锥内沉积在量热计中的横向能量超过电子横向能量的20%,则电子不符合隔离标准。同样,如果半径锥体内轨迹的横向动量的标量和(不包括与电子匹配的轨迹)大于电子的15%,则排除候选电子。此外,每个候选电子的轨迹必须与主顶点匹配。这要求其横向冲击参数的显著性满足,其中为不确定度,且主顶点到被测点的纵向距离满足。为了抑制强子被误认为电子所导致的背景,信号电子必须满足所有基线标准以及“严格”识别标准[65],并且具有。
通过结合ID和μ子光谱仪中形成的带电粒子轨迹或将ID轨迹与与最小电离粒子兼容的量热计中的能量沉积相匹配来重建候选μ子[66]。基线μ子需要具有和,并满足“宽松”的识别标准[66]。通过要求μ子轨迹满足和来保证轨迹到顶点的匹配。信号介子必须满足“介质”识别标准,并且必须具有。此外,信号μ子必须是隔离的,要求μ子周围半径锥体内所有轨迹的标量和小于μ子的6%。
小半径(small-R)候选射流由颗粒流物体[67,68]建立,使用半径参数为的反算法[69,70]。粒子流算法将ID中的轨迹信息和量热计中的能量沉积信息结合起来,形成射流重建的输入。喷气式飞机需要有和。为了拒绝源自堆积相互作用的射流,候选射流必须满足“紧密”射流顶点标记(JVT)标准[71]。包含b强子衰变的小r射流使用一种称为DL1r的多元算法,在模拟事件中确定的标记效率为[72,73]。
使用基线轻子定义,应用重叠去除程序来防止模糊重建对象的重复计数。首先,电子-介子重叠是通过去除与电子共享ID轨道的介子来处理的,如果介子被热量计标记,否则就会去除电子。随后,通过拒绝电子内部的任何喷流和随后拒绝喷流内部的任何电子来消除喷流和轻子之间的重叠。同样,如果射流的相关轨道少于三条,并且在一个μ子候选轨道内,射流就会被丢弃。否则,如果介子位于喷流内,它就会被拒绝。
缺失的横向动量(具有大小)定义为一个事件中所有校准物体的横向动量的负矢量和,加上一个基于轨迹的软项,该软项考虑了与主顶点相关的能量沉积,但不考虑与任何校准物体相关的能量沉积[74]。
最后,利用反算法从选择的小r射流构造大半径(大r)射流。为了减少软辐射的影响,去除小于大r射流5%的组成小r射流。这些重新聚集的大r射流的质量必须大于。
摘要
1 介绍
2 ATLAS探测器
3.数据和模拟事件样本
4 事件重建
构造和对象选择
5 事件选择和分类
6 神经网络训练
7 系统的不确定性
8 统计分析
9 结果
10 结论
笔记
参考文献
致谢
作者信息
搜索
导航
#####
此分析中考虑的所有事件都必须由触发器选择。由于在Run 2期间提高了触发阈值,因此施加了一个要求,以确保在所有数据采集期间都具有充分的触发效率。事件还需要恰好有一个信号轻子(e,)和至少四个小r射流,其中至少一个是b标记的。对满足基线要求的第二个轻子的否决用于抑制具有两个处于最终状态的轻子的事件。为了排除由测不准的射流引起的事件,缺失的横向动量矢量与有序的前导()和次导()射流之间的方位角必须满足条件。此外,事件必须具有横向质量,其中定义为
表2事件选择概述训练区域的操作被细分为低区域控制区域和信号区域,用于顶部重加权区域,用于co+喷流事件和单顶夸克事件的控制区域
在应用这些要求(表2中称为“预选”)之后,主要背景来自和+喷气机生产。通过应用表2中列出的进一步要求来定义神经网络的训练区域,这些要求在不降低对信号的灵敏度的情况下减少背景的数量。要求远高于W玻色子质量峰值,强烈地减少了+喷流和半光子背景。在这些背景过程中,轻子W玻色子衰变是唯一的来源,而在VLQ对产生中,额外的来源可能来自例如Z玻色子衰变为中微子或W玻色子衰变为强子衰变的τ -轻子和中微子。其余的背景来自未检测到一个轻子的双轻子事件。这种类型的背景被对不对称横向质量的要求所抑制,[75,76],这是[77,78]变量的一个变体。后者适用于不能直接检测到两个或更多粒子的特征(例如双轻子事件,其中不能检测到两个中微子),它被定义为
在式中,和是用两组一个或多个可见粒子计算的横向质量,分别用a和b表示,以及缺失的横向动量和的所有可能组合。在计算中,两组可见粒子是不对称的,因为它们由一个被识别的信号轻子组成,其中一个是b标记分数最高的两个射流之一,另一个是另一个射流。给定两种可能的轻子-射流配对,取最小的组合。对于双重事件,分布在顶夸克质量处有一个运动学端点,而额外的源将分布扩展到更高的值。训练区的活动必须完成。对于所考虑的信号,预计至少有一个高顶夸克或SM玻色子的强子衰变。因此,在训练区域至少需要一架大r喷气机。约4%的模拟信号事件在训练区重建,用于纯衰减和VLQ质量为1.2的生产。
背景是本分析中的一个主要背景,在高横向动量下没有准确建模[79,80]。因此,应用了一个重新加权过程,在下面称为“顶部重新加权”。在射流多重度(4,5,6,)的桶中导出重加权因子,作为有效质量的函数,定义为所有重构对象和的标量和。使用标称预测来确定重加权因子和单顶背景的总和,并用线性函数进行参数化。它们来自于一个专用的顶部重加权区域(见表2)中的数据和MC模拟之间的比较,该区域的定义方式与训练区域相同,只是要求相反。为了在分布的尾部有更高的纯度约90%和更少的信号污染,这一要求被加强到。所得的重加权因子应用于每个定义的分析区域中的和单顶夸克事件,这改变了事件产量并导致改进的模型。这可以从图2中看到,图2将重新加权后的数据与顶部重新加权区域的MC模拟进行了比较,也显示了重新加权前的MC期望。
图2
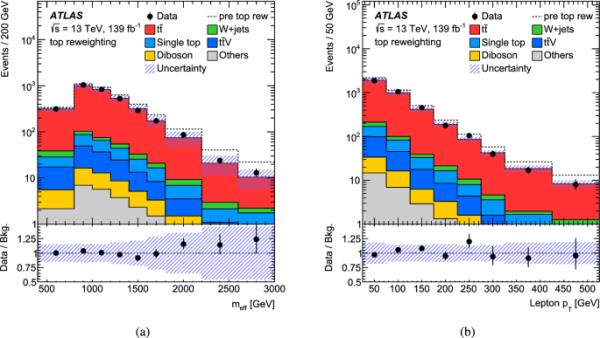
在和单顶背景上应用加权因子后,a和b轻子在顶重加权区域的分布。虚线表示重新加权前的总背景。波段包括统计和系统的不确定性。来自,和+喷气机的次要背景贡献合并到Others中。数据与预期背景的比率显示在图的底部面板中。每个分发版中的最后一个bin包含溢出
图3
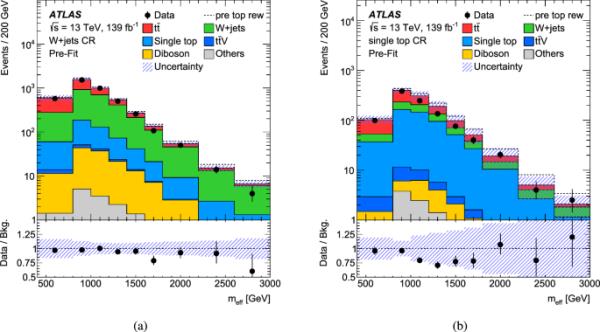
对模拟事件和单顶夸克事件应用顶重因子后,a +喷流CR和b单顶CR的分布。虚线表示重新加权前的总背景。来自,和+喷气机的次要背景贡献合并到Others中。波段包括统计和系统的不确定性。数据与预期背景的比率显示在图的底部面板中。每个分发版中的最后一个bin包含溢出
为+喷流和单顶夸克背景定义了控制区域,以便在各自的背景中得到丰富,并且可以忽略信号的污染。利用W玻色子质量周围的窗口,通过修改要求,定义两个cr与顶部重加权区域和训练区域正交。为了减少这些区域的背景贡献,大r射流的多重性必须小于2,如果存在大r射流,其质量必须低于150。对于+喷气机的CR,通过只选择恰好有一个b标记喷气机的事件来进一步减少事件的贡献。由于生产的横截面比生产的大,所以通过只选择带正电的轻子来获得更高的+射流纯度。在单顶CR中,需要至少两个b-标记的射流,且两个最高的b-射流之间的角间距为0,从而减少了+射流的贡献。表2总结了两种cr的选择标准,图3比较了顶部加权后数据中的有效质量分布与MC模拟中的有效质量分布,并给出了加权前的MC期望。
为了增强信号和背景事件之间的分离,使用了将多个输入变量组合成单个判别器的神经网络。利用训练区域的模拟信号和背景事件对它们进行各种信号假设的训练。对于生产,四个神经网络被训练为不同的分支比率,覆盖该分析敏感的分支比率平面区域:(0.8,0.1,0.1),(0.2,0.4,0.4),(0.4,0.1,0.5),(0.4,0.5,0.1)。同样,考虑到分支比率(0.1,0.1,0.8),(0.4,0.1,0.5)和(0.1,0.4,0.5),三个神经网络被训练用于生产。
表3神经网络训练的输入变量,按信号与背景区分能力降序排序。顺序并不严格,因为它取决于训练NN的VLQ类型和分支比例
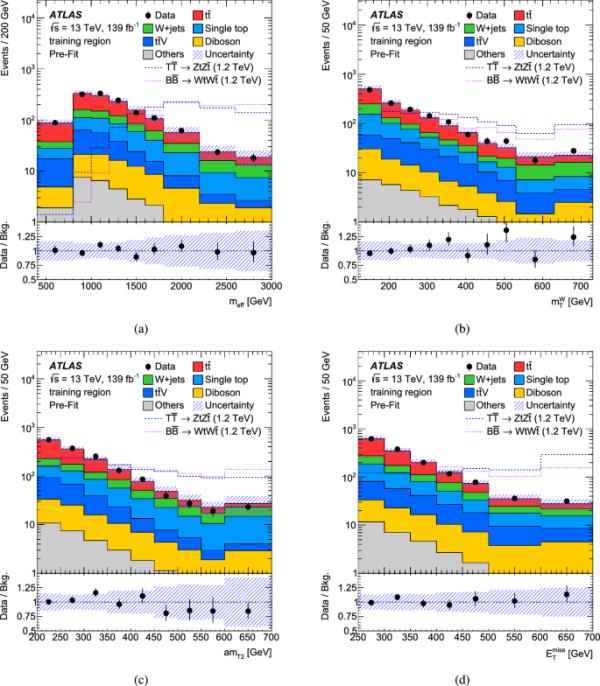
神经网络是使用NeuroBayes包实现的[81,82],它将三层前馈神经网络与输入变量在呈现给神经网络之前的预处理相结合。预处理的主要目的是通过根据输入变量的分离力排序,考虑相关性,并删除除最相关的输入变量之外的所有输入变量,从而促进最优网络训练。输入变量集的选择是基于它们区分信号和背景的能力。表3列出了用于训练至少一个神经网络的输入变量。每一组输入变量由反映信号拓扑的可观测值组成,例如通过高VLQ质量或重聚大r射流的特性。其他重要的变量是b-射流多样性和横向质量,和,用于定义cr和训练区域。检查所有输入变量是否建模良好。作为示例,四个重要输入变量在训练区域的分布如图4所示。
图4
NN输入变量在训练区域的分布:a, b, c, d。来自,和+喷气机的次要背景贡献合并到Others中。和的信号分布,假设VLQ质量为1.2,被覆盖并归一化为总背景预测。波段包括统计和系统的不确定性。数据与预期背景的比率显示在图的底部面板中。每个分发版中的最后一个bin包含溢出
neubayes在训练过程中使用贝叶斯正则化技术来提高泛化性能并避免过度训练。一般来说,网络基础设施由每个输入变量的一个输入节点,加上一个偏置节点,一个任意的,用户定义的隐藏节点数量,以及一个输出节点组成,该节点在区间内给出连续的NN输出分数(),其中接近零的值表示类背景事件,接近1的值对应于类信号事件。对于本分析中的神经网络,隐藏层使用15个节点,训练中信号与背景事件的比例选择为1:1。不同的后台进程根据其预期的事件贡献进行加权。所有的主要背景,+射流,单顶夸克,和,都在训练中使用。对于信号处理,每次训练时将1 ~ 1.5的VLQ质量合并。在组成训练样本时,不同信号质量的事件以相同的横截面进入,以防止横截面大的低质量占主导地位。为了检查潜在的过度训练,只有80%的模拟事件作为训练的输入,而剩下的20%作为测试样本。没有观察到过度训练的迹象。在训练步骤之后,所有模拟信号和背景事件以及观测到的数据事件都由神经网络处理,以获得每个事件的值。对于每个神经网络,训练区域被划分为低CR和SR。
考虑了实验和理论系统不确定性的几个来源。实验不确定性主要与最终状态物理对象的重建和校准有关,而理论不确定性则与MC事件发生器对各种过程的建模有关。分析中最大的系统不确定性的来源与主要背景过程的模拟和射流能量分辨率有关。
对于单顶生产,应用以下与事件建模相关的系统不确定性。通过比较名义MadGraph5_aMC@NLO 8样本与由Pythia 8淋浴的MadGraph5_aMC@NLOand生成的备选样本,来评估ME发生器和parton淋浴之间匹配过程中的不确定性。为了估计潜在事件、部分子雨和强子化建模中的不确定性,将标称样本与Powheg+Herwig 7[83]预测进行了比较。通过独立地将尺度加倍和减半来考虑与矩阵元素计算的重整化和分解尺度选择相关的不确定性。初始状态辐射(ISR)的影响是通过A14调谐的变化来估计的。同样,与最终状态辐射(FSR)相关的不确定性是通过将最终状态parton-shower排放的重整化尺度变化2倍来评估的。通过将标称样品与参数设置为的备选样品进行比较,来评估与该过程的矩阵-元素计算与parton淋浴相匹配的尺度选择相关的不确定性。PDF的不确定度使用PDF4LHC15组合PDF集获得[84]。单顶过程建模中一个主要的系统不确定性源于对NLO之间和NLO处的干扰的处理。通过比较使用图去除方案生成的生产标称样本与使用图减去方案的替代样本来估计不确定性[45,85]。最后,另外30%的归一化不确定性被分配给来自+重味喷射器生产的事件[86]。
顶部重加权过程中的不确定性来自于参数化函数的选择形式和重加权区域中事件的统计不确定性。这些是通过改变参数化函数的标称值,利用拟合参数的不确定性并考虑它们的相关性来解释的。确定重新加权的四个喷气箱中的每一个都被视为一个独立的不确定性来源。
对于所有其他考虑的过程,即+射流、二色子、、和生产,重整化和分解尺度独立地以两个因子变化。根据Sherpa 2.2.1和数据之间的比较[87],将30%的不确定性分配给+喷气过程的重风味成分。
在剖面似然拟合中没有自由浮动归一化参数的背景被赋予理论截面不确定性。对于该过程,分配的不确定性为11%[88],不确定性分别为15%和12%[88]。二色子生产的截面不确定度为6%[89],+射流工艺的截面不确定度为5%[90]。
除了理论的系统不确定性外,分析中还考虑了与探测器相关的不确定性,主要是射流能量分辨率[68]。其他与射流相关的不确定性来自于射流能量尺度、射流质量尺度和分辨率、JVT要求的效率以及b-射流识别[72,91]。与轻子相关的不确定性来自于轻子识别、分离和重建的效率,以及轻子的能量尺度和分辨率[65,66]。进一步的实验不确定性与计算中航迹软项的尺度和分辨率有关[92]。对总系统不确定度的额外贡献来自综合光度和堆积剖面的不确定度。
盒状神经网络输出分布的信号富集部分(> 0.5),以及低、+射流和单顶cr中的事件总数用于测试信号的存在。对于假设检验,按照RooStats[94]中实现的一种改进的频率方法[93],并将影响信号和背景期望的系统不确定性作为干扰参数考虑在内,分别对七个神经网络中的每一个进行分类的轮廓似然拟合。
分箱似然函数被构造为所有箱上泊松概率项的乘积。它取决于信号强度参数,一个乘以理论信号产生横截面的因子,以及一组干扰参数,这些参数在高斯或对数正态先验的似然函数中受到约束。低、+喷流和单顶cr主要用于控制+喷流和单顶背景的归一化,在似然函数中包含了额外的无约束归一化因子(、、和)。在一个容器中预期的事件数量取决于规范化因素以及干扰参数。干扰参数根据相应的系统不确定性调整信号和背景的期望,它们的拟合值对应于最适合数据的量。
为了避免重复计算自由浮动背景过程的归一化不确定性,在考虑其建模中的系统不确定性时,仅包括CRs和SR之间的形状影响和可接受性差异。当信号区域内箱体间的统计波动较大时,对系统变化的模板采用平滑算法。此外,所有系统变化的模板都是对称的。与主要背景过程的建模有关的一些主要的系统不确定性是片面的,并且通过镜像不确定性而对称。为了简化拟合程序,仅在系统不确定性影响事件产量超过1%的情况下才包括干扰参数。系统不确定性源的归一化和形状分量在本程序中分别处理。
检验统计量定义为轮廓似然比,,其中和是同时使似然函数最大化的参数值,是使似然函数在固定值下最大化的干扰参数值。通过设置检验统计量来检验观测数据与纯背景假设的相容性。使用CL方法[93]和渐近逼近[95]计算每个考虑的信号场景的信号产生截面的上限。如果信号产生横截面的值(由参数化)产生CL值,则认为给定的信号场景在置信水平(CL)上被排除。
对每个神经网络执行仅限背景的似然拟合。对于不同神经网络的拟合,得到的+射流和单顶过程的归一化因子有所不同:在+射流之间和之间,在+射流之间和之间,以及在单顶之间和之间。单顶贡献的减少似乎很大,但它小于模拟和tW过程之间干扰的名义方案和替代方案之间的差异,这在第3和7节中有描述。通过与模拟数据的比较,验证了拟合后的分布。作为示例,使用VLT信号with和VLB信号with进行神经网络训练的图如图5所示。对于使用VLT信号进行训练,三个cr和信号区域中每个过程期望的相应事件数以及观察到的事件数和质量为1.2时的期望信号产量如表4所示。由于模拟干涉的不同方案,单顶产率存在很大的不确定性。由于各种系统不确定性之间的强(反)相关性,总背景的不确定性小于单独过程的不确定性。
图5所示的两种训练案例和另一种VLT信号的训练案例的信号区域分布如图6所示。对于这三种情况或使用其他训练过的神经网络时,没有观察到与SM期望的显著偏差。
图5
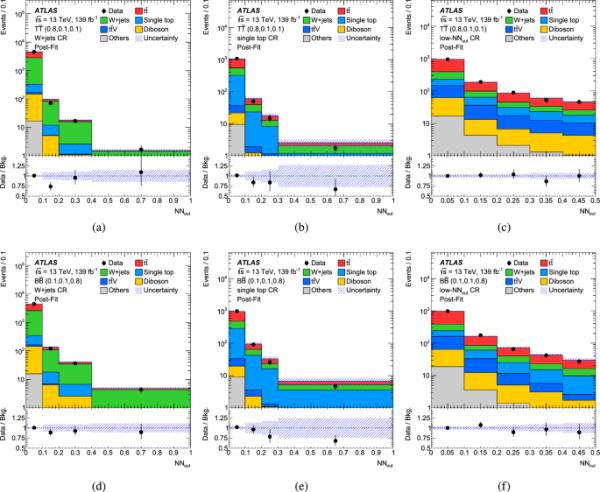
对于考虑VLT信号(上面板)和VLB信号(下面板)的神经网络训练,经过仅背景拟合(Post-Fit)后,+流CR(左图)、单顶CR(中面板)和低CR(右面板)中的数据和背景期望。来自,和+喷气机的次要背景贡献合并到Others中。条带表示拟合后的不确定度。下面的面板显示了数据与背景期望的比率
表4观测数据事件产量和期望背景事件产量及其总不确定性背景后的控制和信号区域只适合考虑一个针对具有分支比的VLT信号训练的神经网络。为了比较,给出了质量为1.2、分支比为的VLT信号的事件产率
图6
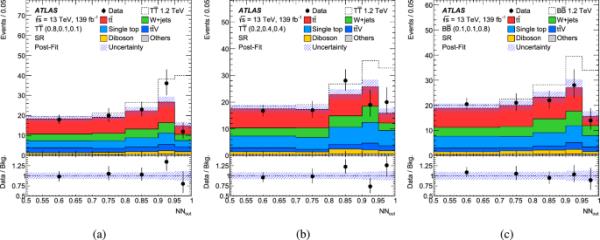
同时背景只拟合(Post-Fit)后的信号区域的数据和背景期望对一个神经网络训练的数据进行拟合(Post-Fit),该神经网络训练的对象是a VLT信号,b VLT信号,c VLB信号。来自,和+喷气机的贡献被合并到Others中。期望的预拟合信号分布与各自的训练相对应的信号分支比被添加到背景期望之上,使用信号质量为1.2。波段表示统计和系统的不确定性。数据与背景期望的比率显示在图的底部面板中
T夸克和B夸克对产生截面的上限在95% CL处计算。对于每个信号质量和分支比,选择给出最严格期望极限的神经网络。将所得的横截面极限与理论横截面进行比较,确定信号质量的排除极限。计算了T夸克和B夸克在弱同位旋单线态和双线态中的极限,具有依赖质量的分支比,以及纯夸克和衰变夸克的极限,其中后者对应于前面提到的(T, B)双线态。对于重态情景,来自VLQ伙伴的贡献要么不考虑,导致保守的限制,要么考虑假设质量简并VLQ。质量差最多只允许有几个,这样从重态的一个成员到另一个成员的衰变就被抑制了[4,6]。同样,对于质量退化双重场景,使用第6节中描述的7个NN,并如上所述选择具有最严格期望限制的NN,即不训练额外的NN来潜在地增加对两个双重成员的附加产量的敏感性。
上述模型中VLQ质量的预期下限和观测下限列于表5,如图7所示。统计不确定度对质量极限的影响大于系统不确定度。然而,后者是不可忽略的,对于pure()衰减的情况,它将预期的下限降低了约40(70),达到1.45(1.42)。对于表5中的三种t -夸克情景,使用Run 2数据的一个子集,在相同的最终状态下,获得的质量极限比之前的ATLAS分析高300-400[16]。这种改进只是部分归功于更大的数据集,因为VLT质量为1.4的横截面的预期限制在纯VLT的4.5倍和SU(2)单重态的7.7倍之间得到了改善。特别是当分支分数变成Zt变得更小时,主要的影响来自于在几个分支比率下训练神经网络,而不是像以前那样使用单个SR进行切割计数分析。表5中得到的前5个场景的质量极限也优于使用36 fb的所有ATLAS结果组合得到的相应极限[26],除了T单重态场景中观测到的极限弱于预期极限。假设质量简并VLQ的弱同位旋双重态得到了VLQ质量的最强下限1.59。
表5特定VLQs对生产的预期(Exp.)和观察(Obs.)质量极限(T,B,X)在某些衰变情况下是相对应的导致SU(2)单重态或双重态表示,或者衰变为一个特定的最终状态。在双重情况下,co不考虑VLQ合作伙伴的贡献,导致co保守的限制,除了最后一行当e假设重态中的vlq是质量简并的。由于分析不区分粒子和反粒子,所以极限也适用于类矢量X因为它只会衰变成Wt。同样,(T,B)双重情景对应于(X,T)双重情景
图7
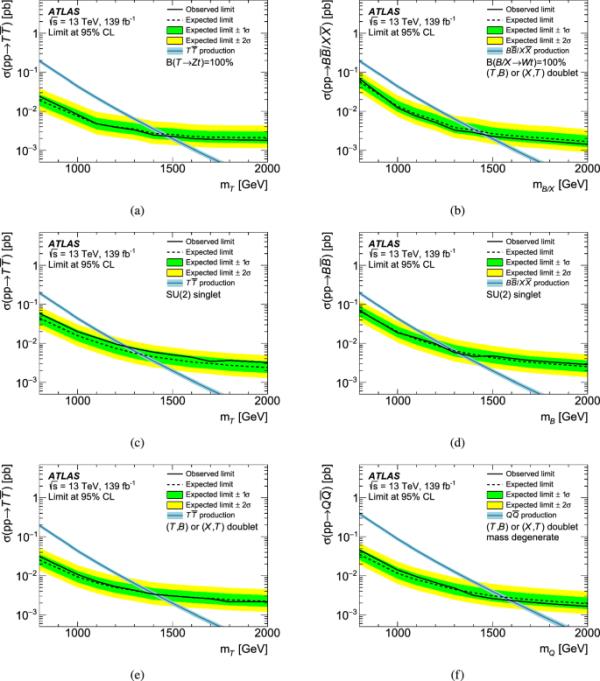
a、b、SU(2)单重态表示中的ca T夸克、SU(2)单重态表示中的d a b夸克和SU(2)双重态中的e a T夸克的期望和观测到的信号截面上限。在双线态的情况下,未考虑的类矢量夸克的贡献被忽略,导致保守的限制。考虑T夸克和B夸克贡献的SU(2) (T, B)双重态情景如(f)所示,假设质量简并vlq。理论曲线的厚度表示来自pdf、尺度和强耦合常数的理论不确定度
图8
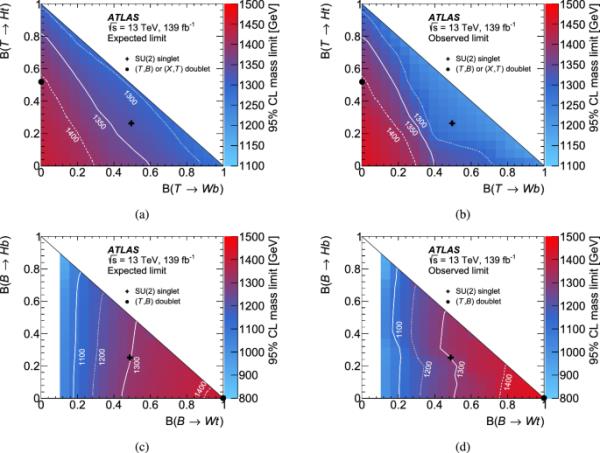
(上一行)和(下一行)生产的预期(左)和观察(右)质量限制。使用神经网络计算质量极限,在每个信号质量和分支比点给出最严格的期望极限。白线表示质量排除线。黑色标记表示SU(2)单线态和双线态在质量大于800的情况下的分支比,它们大约与VLQ质量无关。由于分析不区分粒子和反粒子,(T, B)重态中B夸克的质量不相容与(X, T)重态中X夸克的质量不相容是等价的。白色区域表示质量极限在800以下
除了对特定模型和分支比率的限制外,信号质量的下限是作为T和B分支比率的函数设置的。得到的期望和观测到的质量极限如图8所示。正如预期的那样,在和附近的区域发现了最高的灵敏度。对于T夸克,混合ZtHt衰减模式的灵敏度大于ZtWb衰减模式的灵敏度。在B夸克的情况下,如果B的分支分数衰变为希格斯或Z玻色子和底夸克增加,则灵敏度降低。在SU(2)单线态分支比周围,类矢量T夸克的观测极限与预期极限之间的差异并不显著,如图7(c)所示。它们是由经过分支比训练的神经网络得到的分布结果。在图6(b)对应的信号区域的最后一个bin中,数据略高于预测的SM背景。
搜索成对产生的类矢量T夸克和B夸克,分别带电荷和,在恰好有一个孤立轻子,至少有四个喷流(其中一个是B标记的)和高缺失横向动量的事件中进行。这一分析是基于在大型强子对撞机中质子-质子碰撞的ATLAS实验收集到的数据,对应的综合光度为139fb。假设衰变为W、Z或希格斯玻色子和第三代夸克,几个神经网络对T和B夸克的不同分支比率进行了训练。该分析考虑了类矢量夸克的所有可能的衰变,但对和衰变模式最为敏感。由于分析没有区分粒子和反粒子,所以极限也适用于带电荷的向量X。
没有观察到与标准模型期望的显著偏差,并且在各种衰变分支比情景下,T和B夸克的成对产生截面作为其质量函数的95% CL上限得到了推导。弱同位旋单重态模型中T夸克和B夸克的质量下限分别为1.26和1.33,双重态模型中T夸克的质量下限为1.41。对于重态,不考虑VLQ伙伴的贡献,导致保守限制。当考虑纯态和衰变时,质量的下限为1.47和1.46,其中后者对应于(T, B)或(X, T)重态,也适用于衰变。对于所讨论的三种t -夸克情景,使用Run 2数据子集在相同的最终状态下获得的质量极限比之前的ATLAS分析高300到400。对于(T, B)和(X, T)弱同位旋重态,T, B和X的最强下限为1.59,其中两个VLQ伴子都被认为是质量简并的。最后,对所有可能的分支比推导出T和B夸克质量的下限。
下载原文档:https://link.springer.com/content/pdf/10.1140/epjcs10052-023-11790-7.pdf


