

详细了解公共交通服务的使用情况和乘客负荷情况,是设计、运作和调整公共交通服务的基础。传感技术的进步使交通运营商能够连续、一致地监测客流的变化。有越来越多的文献使用监督学习模型,根据历史观察直接计算乘客数量。然而,来自自动传感器的不完整、不准确和有偏见的数据给这一过程带来了挑战。本文提出了基于两个主要数据源的新型监督学习模型来估计公共交通服务的车载负荷概况:(1)由自动乘客计数系统(APC)收集的服务车辆子集的有限数据;(2)由自动收费系统(AFC)收集的票价数据。具体考虑到所开发的模型可以跨不同路线转移。这是由于服务车辆上的自动乘客计数器通常“覆盖范围有限”。我们引入了一系列新模型,其中包括一个优越的基于分段的模型,该模型在模型可移植性和准确性方面有了显着改善。所提出的方法在一条运输线路的不同路段采用不同的方法。提出的模型应用于澳大利亚墨尔本的三条有轨电车线路,其中自动化数据存在各种各样的缺点。试验结果表明,该模型可以在不依赖历史观测的情况下,推广应用于其他公交路线。这将使运输运营商能够减少所需设备的数量,并以更具成本效益的方式监测服务的利用情况,特别是在公共交通网络中,亚铁覆盖通常是不完整和负面倾斜的。有关服务使用情况的资料,不但有助营办商因应乘客需求的变化,亦有助乘客规划行程,避免服务上挤迫。
快速的城市化给交通基础设施带来越来越大的压力。客流量估算是公共交通网络设计、运营和调整的基础。对于战略规划的应用,对区域总体水平的常规旅行需求量的基本了解通常就足够了。这些信息可以通过四步旅行需求预测模型获得(McNally 2007)。然而,对于操作应用程序,需求变化信息正变得越来越相关和必要。
公交行业最近开始利用需求信息来支持数据驱动的决策。例如,公共交通运营商可以调整服务频率以适应乘客需求的变化,针对乘客需求低的目标地区开发需求响应服务,向客户提供拥挤程度的信息,并帮助他们规划行程,以避免服务过度拥挤。与战略层面的模型相比,这些策略的制定需要更深入地了解详细的乘客需求信息,包括每天和一天内的变化。了解对服务中断、特殊事件、限制(如COVID-19)和运营干预(通过“前后”分析)的需求响应尤为重要。向运输运营商提供这些事件期间的需求模式,可以提高他们应对不确定性的能力,为客户提供更可靠、更高效的服务。然而,通过船上调查收集需求数据的传统方法是劳动密集型和昂贵的。因此,操作应用程序的样本大小不可避免地很小。
大多数交通运营商都认识到,交通智能交通系统(ITS)产生的数据,包括自动乘客计数(APC)和自动收费(AFC)系统,包含有价值的信息,可以支持运营决策。APC系统按停站和时间记录详细的上下车需求。然而,由于预算限制,APC系统通常安装在车队的一部分车辆上,因此无法直接监控所有单独行程的乘客负载。AFC系统最初是为财务和收入目的而设计的,但现在被认为是了解旅游需求模式的丰富数据源。越来越多的文献试图从AFC数据中推导出原点-目的地流矩阵(trsampanier等人,2007;Pelletier et al. 2011;Gordon et al. 2013;Nassir et al. 2015, 2017, 2019;Munizaga et al. 2020),并分析公交乘客模式。这些数据通常比APC系统收集的直接乘客数量更容易获得。然而,由于非卡用户、免费服务区、可能的逃票等导致的信息缺失,许多城市无法获得高质量的AFC数据。因此,该领域出现的一个具有挑战性的问题是高质量数据的低覆盖率。
在本文中,我们的目标是利用大多数公交运营商可以访问的数据源,并开发一个数据驱动的模型,以可靠地估计每次服务行程的负载概况,特别是那些没有直接乘客数量数据的旅程。我们提出了一组监督学习模型,使用从APC系统收集的现有观测数据中获得的真值标签。考虑到APC系统的覆盖限制,我们解决了两个问题:(1)同路线估计,其中监督学习模型使用来自同一过境路线的数据进行训练和测试;(2)交叉路线估计,其中使用直接测量路线的数据训练的模型应用于没有任何历史观测的新路线。这两个问题都是用澳大利亚墨尔本的三条有轨电车线路来检查的,在那里,被动收集的数据存在各种缺点。例如,24条航线中只有3条配备了APC系统。此外,就AFC数据而言,逃票率相对较高,并且在中央商务区(CBD)设有免费有轨电车区,乘客无需乘坐或乘坐有轨电车服务。
案例研究结果表明,与直接估计AFC记录相比,监督学习模型产生了更准确的客运量估计。一个重要的发现是,通过将监督学习与上车(或下车)流和上车负载之间的直接相关度量相结合,可以提高模型的准确性。另一个重要的发现,特别是在跨路线估计方面,是一种基于路段的估计方法,它对过境路线的不同路段应用不同的方法,可以产生更好的可转移性。该方法是基于客流与独立解释变量之间的关系在不同航段之间可能并不总是一致的假设而开发的。对于入站方向的上游站点,大多数行程最终在CBD结束,上车流量可能受行程生产特征(如居住人口)的影响最大,并且预计在不同路线之间是一致的。然而,乘客下车流量可能主要受到行程目的的影响,而不同路线的行程目的可能会有很大差异。另一方面,对于中游和下游站点,上车旅客没有共同的目的地,因此上车流不依赖于不同路线的共同特征。因此,该方法不是利用沿路线统一参数的监督学习模型,而是采用单独的估计方法对不同航段/方向的上下车流量进行估计。
据我们所知,本文是第一次尝试将监督学习模型应用于客流的可转移估计,其中训练和测试数据来自不同的路线。这项研究具有重要意义,特别是在APC和AFC数据覆盖率低或倾斜的公共交通网络中。开发的模型可以帮助减少所需传感器的数量,以更有效和经济地监测服务利用率。
本文的其余部分组织如下。现有文献在“文献综述”中进行综述。“方法论”说明了问题所在,并描述了本文提出的模型框架。“案例研究”详细阐述了数值实验的设置,其中所提出的方法在澳大利亚墨尔本的三条有轨电车路线上进行了测试。结果在“结果”中进行了介绍和讨论。在“结论和未来的工作”中,讨论了未来可能的改进。
公共交通客流的估算是公共交通服务规划和运营管理的基础,在交通研究中受到广泛关注。传统上,交通负荷估计是通过一个连续的四步模型来实现的(McNally 2007):(1)根据土地利用和人口统计信息生成每个区域的交通流量;(2)考虑土地利用和网络可达性,分配特定出发地和目的地的行程;(3)利用用户行为分析构建的选择模型进行公共交通出行选择;(4)根据网络结构将行程分配到特定的路线上。然而,四步模型仅构建了在常规一天的特定时间段内的出发地(OD)对之间的关系。虽然这些模型对战略规划很有用,但它们无法考虑乘客需求的日常和单日变化,以及服务变化对需求的反应。这为运营管理和详细的服务规划分析造成了数据缺口。
为了解决这一差距,动态交通模型已经开发出来,其中包括模拟技术,如BusMezzo (Cats 2011), FastTrips (Khani 2013),以及流行的商业工具如PTV Visum和Omnitrans提供的基于时间表的交通分配方法。这些模型将乘客分配视为一系列基于旅行者进度的旅行决策,从而能够表示旅行者对网络中各种条件的响应。这些模型需要一套规则来表示乘客的行为,并对公共交通中需求和供给特征之间的相互作用做出假设(Gentile和N?kel 2016)。然而,其中一些模型需要明确的偏好调查,这些调查是专门为估计乘客行为而设计的,这可能是劳动密集型的,并会给结果带来偏见和不确定性(Kagho et al. 2020)。此外,模拟具有不同行为的大量智能体的计算成本对动态运输模型提出了重大挑战。虽然这些模型适用于策略性规划,但它们无法提供个别行程的实时客运量估计。
智能交通系统(ITS)的主要变化是由从各种来源收集的数据量催化的。自动乘客计数(APC)系统提供准确和自动的乘客率记录,并越来越多地被运输运营商采用。然而,由于预算限制,通常的做法是在车队车辆的一个子集上安装APC系统(Strathman 1989;Siebert and Ellenberger 2020)。虽然这种方法可以获得整体客流分布,但它不足以实时监测个别行程的客流量。在没有每次服务行程的APC数据的情况下,一些研究使用APC数据作为基础事实标签的监督学习模型(Moreira-Matias and Cats 2016;Jenelius 2019)。监督学习模型能够推断客流与其他自变量(如历史需求、停留时间、车头距等)之间的复杂关系。考虑到上述自变量,即使没有直接测量,这些推断关系也可以用来实时估计客运量。然而,监督学习模型的一个挑战是它们只考虑APC系统的运输路线。没有APC系统的运输路线缺乏历史观察,因此必须采用从其他路线训练的监督学习模型。这通常是一个复杂的问题,因为客流和其他独立变量之间的关系可能在不同的路线上不一致。不幸的是,迄今为止还没有研究在没有任何历史观察的情况下检验监督学习模型在交通路线上的应用。
与APC系统相比,自动收费(AFC)系统通常用于整个公共交通车队的财务目的。AFC系统通常记录登机交易的时间和地点,这些交易每天从机上(或固定的)票价验证设备转移到数据存储设施。为了使用AFC数据重建乘客的旅行链,已经进行了许多尝试(Munizaga和Palma 2012;Gordon et al. 2013;Nassir et al. 2015, 2017, 2019)。这些行程链模型通常与其他交通数据源(如自动车辆定位(AVL)和一般交通馈送规范(GTFS)数据)相融合,以推断单个轨迹的上车和下车位置。几项研究揭示了AFC数据在构建负荷剖面中的力量(Chu和Chapleau 2008;Luo等人,2018),利用行程链模型监测服务利用率。然而,根据AFC数据的覆盖范围和准确性,可能存在未正确记录或无法通过行程链模型推断的行程。例如,在芝加哥(Miller et al. 2018),只有约85%的乘客使用车费卡登机,而其他人更喜欢纸质票或现金选择。在智利的圣地亚哥(Cantillo et al. 2022),逃票是一个严重的问题,引起了对运营成本回收的严重关注。在墨尔本,中央商务区的免费有轨电车区是收费系统的盲点。此外,符合票价要求的乘客,例如持有票价通票或在转乘/联运行程中验证了票价卡的乘客,可能不需要在特定的服务行程中刷卡。此外,行程链模型依赖于各种行为假设来推断下车位置,这可能会引入额外的不准确性。这些是AFC数据不准确的一些潜在来源,在不同的机构之间可能有所不同。
一些缺失的数据可以通过使用扩展因子缩放OD矩阵来解决,假设未知起点和目的地的旅行分布与推断起点和目的地的旅行分布相似(Gordon et al. 2013)。扩展系数可以根据已知od的交易部分的分布来计算。但是,这种处理不能适用于失踪旅行的分布不均匀的情况。如果时空旅行模式存在显著差异,简单的扩展方法可能会有偏差和误导(Gordillo 2006;Munizaga and Palma 2012)。例如,在墨尔本的免费有轨电车区,在AFC数据中没有整个子区域,缩放可能不是数据输入的有效解决方案。
总之,从不完整的APC或AFC数据中得出单个行程的无偏乘客负荷测量是具有挑战性的。虽然一些研究已经证明了使用APC数据来训练监督学习模型的潜在价值,但这些模型在不同运输路线上的可移植性仍有待确定。对于个人旅行,AFC数据通常比APC数据更容易获得,但在许多城市,AFC数据经常出现负面偏差。这些问题促使我们的研究改进现有的公共交通服务负荷估计模型,这些模型使用有限的、不完整的和倾斜的数据源。
给定一组服务行程和站点,主要目标是估计特定行程在特定站点的乘客负荷。一种常见的方法是使用AFC数据重构用户的出行链(Gordon et al. 2013;Munizaga and Palma 2012;Nassir et al. 2015,2017,2019)并汇总客流以构建每次行程的负载概况(Luo et al. 2018)。然而,由于固有的限制,例如收费数据中的记录不完整、不一致或不准确,这种方法可能无法产生准确的负载概况(Kurauchi和Schm?cker 2017)。
例如,来自墨尔本有轨电车服务的AFC数据受到各种需要解决的限制。此前的一项调查显示,2012年6月的触碰率为37%。数据的缺失可归因于几个因素。首先,墨尔本有轨电车服务的逃票率很高(Delbosc和Currie 2016),因为乘客可以从任何门上车,而无需与司机接触,导致逃票率上升。虽然检票员是受雇检查有效车票的,但他们只在一些随机选择的站点登车,导致大多数行程未被检查。其次,虽然乘客应该在登机时触摸,但如果他们持有车票或从其他服务(火车,有轨电车或公共汽车)转乘,他们是合规的。墨尔本的另一个具体问题是,在中央商务区(CBD)有一个免费的有轨电车区,乘客们被积极劝阻上下车。如果错过行程的比例在服务、路线和行程中均匀分布,则可以基于具有确定的起点和目的地的交易分布应用扩展因子(Gordon et al. 2013)。然而,对于墨尔本来说,缺失信息的分布可能是不均匀的。具体来说,与其他站点相比,免费有轨电车区域内的大量行程没有记录。免费有轨电车区域的边界也很关键,因为一些乘客可能会冒着多走几站而没有上车的风险,导致上车率降低。因此,简单的扩展系数可能无法有效地准确估计客运量(Munizaga et al. 2020)。
自动乘客计数(APC)系统于2020年引入墨尔本有轨电车网络;然而,它们目前只安装在三条线路上的一小部分有轨电车上。由于预算的限制,使其成为数据收集的主要模式并获得每辆车的精确乘客人数仍然具有挑战性。尽管覆盖范围有限,但从这些APC设备收集的数据可以作为可靠的地面真实数据,用于训练机器学习模型,并发现乘客负荷与其他自变量之间的相关性。为不同目的收集的其他类型的数据可能会捕获缺失的信息片段。
考虑到APC系统的覆盖范围,我们提出了两个监督学习问题:(1)同路线估计,(2)交叉路线估计。同路估计适用于在车队子集上安装APC系统的路线。它利用APC系统在与地面真实标签相同的路线上收集的乘客数量。交叉路线估计是为没有任何APC系统的路线设计的,并使用路线上的乘客数量作为地面真实值标签。该模型使用从带有APC系统的路线收集的数据进行训练,然后将其转移到缺乏历史观测的不同路线上,以估计服务负载。
“估计框架”一节介绍了适用于前面提到的监督学习问题的估计框架。“特征开发”一节全面概述了从外源数据中提取的输入特征,这些特征作为监督学习模型的输入。
本节针对同路估计和跨路估计问题提出了几种解决方法。考虑一组服务行程,其中公交路线r在一个方向上有一组站点。主要目标是估计在第i站的行程的载客量。我们假设给定的行程有以下几组信息:
1.
从外源数据(参见“特征开发”)导出的行程第i站的特征向量。令,和分别表示上车流、下车流和客流量所使用的特征向量。
2.
由不完全AFC数据推导出行程i站至j站的乘客OD流
基准
一种直接的方法是将特征输入监督学习模型并直接估计客运量。令用客运量的真值标签训练的监督学习模型为。行程第i站的估计客运量由下式给出:
(1)
乘客负荷也可以通过模拟上下车流量来间接估计。令和分别表示用上车流和下车流的真值标签训练的监督学习模型。行程第i站的预计上车和下车流量由下式给出:
(2) (3)
最后,根据上下客流量4计算估计客流量:
(4)
然而,这两种估计方法忽略了上车流、下车流和客流量之间的关系。许多研究人员认为,这些关系反映了客流数据中的长期依赖关系(Li and Cassidy 2007;McCord et al. 2010;Sun et al. 2021;Cheng et al. 2021)。例如,每站下车的乘客数量与车上的载客量高度相关,因为下车的乘客必须在前一站上车。为了捕捉这些关系,我们提出了三种不同的估计方法:两阶段估计、基于od的估计和基于分段的估计。
两级负荷估计
两阶段法捕获了机上载客量和下车流量之间的关系。它包括一个粗略的估计和一个校准步骤,使用估计的机上乘客负荷。在校正步骤中,将估计的乘客负荷作为额外信息(附加特征)纳入下车流量的估计。
首先,我们使用公式2 - 4训练登机和下车的单独模型,以获得训练和测试数据的负载的粗略估计。这为我们提供了行程中每一站乘客载客量的粗略估计。
为了建立下车流与车上乘客负荷之间的关系模型,我们将前一站的乘客负荷纳入下车模型的特征空间。前一站的客运量由式5计算。
(5)
然后,我们用和训练一个校准模型来改进下车流的估计。然后结合特征向量和前一站的乘客负荷,更新行程第i站的下车需求。
(6)
最后,用公式计算第i站行程的最终客运量():
(7)
OD-based负荷估计
在不同的路线上,客流与输入特征之间的关系可能不一致,这可能会在使用其他路线的真实标签训练模型时引入跨路线估计的偏差。另一方面,AFC数据,尽管有不完整、不一致和不准确的记录,但可用于所有服务行程,并可能保留特定路线的独特特征。
基于od的估计将监督学习模型与来自AFC数据的需求模式集成在一起。基于OD的模型使用监督学习模型和从AFC数据中检索的OD流矩阵,而不是独立估计上车和下车量。对于由输入和输出记录组成的AFC数据,可以通过汇总单个轨迹直接导出OD矩阵。在只有点击数据的城市,OD矩阵可以通过行程链模型推导(Nassir et al. 2011;Munizaga and Palma 2012;Nassir et al. 2015, 2017, 2019)。另外,OD矩阵可以从其他数据源(如人力调查或战略模型)派生。虽然静态OD矩阵不能反映行程层面的客流,但该方法使用静态OD矩阵来生成每个站点的上车和下车概率。基于od的估计可以进一步分为基于登机的估计和基于降落的估计。
基于登机的负荷估计方法使用监督学习模型估计登机流量,并使用从AFC数据中检索到的OD流矩阵从登机需求中计算出下车需求。首先,我们训练上车模型,并应用Eq. 2预测行程第j站的上车流。
然后,通过汇总各个服务行程的乘客数量,由AFC OD概率构造出下车概率。表示在第j站上车的乘客在第i站下车的概率。表示AFC数据记录的从第j站到第i站的客流。降落概率计算如下:
(8)
在得到j站行程的上车流量估计和下车概率后,可以直接从上车量和OD分布估计下车流量。假设同一路线上的行程具有相同的下车概率。行程第i站下车流量估算公式为:
(9)
通过对各站点上下车流量的估计,由式4计算第i站点的行程负荷。
基于下车的估计基于下车的估计使用监督学习模型估计行程第j站的下车流量。然后使用登机概率估计登机流。与Eq. 8计算出的下车概率类似,从AFC数据也可以导出从第i站到第j站的上车概率,表示在第j站下车的乘客来自第i站的概率:
(10)
然后,行程第i站的上车流程计算如下:
(11)
通过对各站点上下车流量的估计,由式4计算第i站点的行程负荷。
图1说明了(a)间接估计(b)两阶段估计(c)基于登机的估计和(d)基于降落的估计的结构。粗体线表示用于估计客运量的信息流。与间接估计相比,所有其他方法都包含额外的信息来模拟登机流、下车流和乘客负载之间的依赖关系。两阶段估计方法利用监督学习模型来捕捉上车和下车客流之间的关系。另一方面,两种基于OD的方法通过从AFC数据中得到的OD分布概率来连接上车流和下车流。
图1
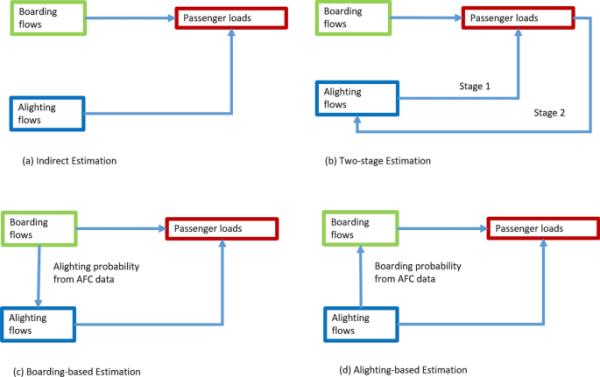
估算框架的结构:间接估算模型;b两阶段估计模型;c基于登机的估计模型;(d)基于闪电的估计模型
线段based估计
两阶段估算法和基于od值的估算法都是先估算上下车流量,然后再计算客流量。然而,当在特定站点对上车或下车流量的估计不准确时,存在潜在的风险。这些误差可能向下游传播,导致估计负载有偏差,即使对下游停止的估计是完美的。为了减轻这种级联故障的影响,提出了一种基于路段的估计方法,其中使用混合方法估计不同路段的站点。
我们首先使用特征向量和ground-truth标签训练登机模型和下车模型。这使我们能够使用公式2和3获得上车流和下车流的估计
接下来,将路线的站点分成三个段:高峰段(PS)、入站段(IS)和出站段(OS)。高峰时段通常包含研究期间的主要目的地,如中央商务区(CBD),这里集中了大多数金融、法律、行政和零售设施,吸引了各种各样的工人。位于高峰段上游的站点被归类为入站段,因为在该区域产生的大多数行程很可能在高峰段结束。位于高峰段下游的站点被称为出站段,因为它们主要服务于从高峰段出发的行程。
在入站部分,大多数旅行最终都是在CBD的共同目的地。因此,不同路线上的行程以相似的方式产生,不同路线上的上车流量可能受行程生产特征的影响最大。例如,入境段产生的旅行次数可能与入境段内地区的人口成正比。因此,我们采用监督学习模型,通过Eq. 2来估计登机流。关于下车流,终止入站段的行程不共享共同目的地。下客流量与其他自变量之间的关系可能在不同的路线上有所不同。因此,入站段的下车流量由公式8 - 9所示的基于登机的方法估计。这种方法完全依赖于AFC的需求模式,它捕获了特定路线的独特特征。
相比之下,在出境游中,来自高峰时段的旅行更有可能表现出类似的吸引力模式。预计在不同路线的下车流量和其他独立变量之间也存在类似的相关性。对于出站段的站点,我们采用公式8 - 9中概述的基于停车的方法。下车流采用监督学习模型计算,上车流由上车概率决定。
因此,进出站站上下车流量由下式计算。令和分别表示行程第i站上车和下车流量的最终估计。
(12) (13)
为了防止负荷估计误差沿负荷曲线传播,我们从入站段的第一站开始计算负荷;而对于出站段中的站点,我们从最后一个站点开始计算负载。第一站和最后一站的负载总是为零,并且估计误差只会在各自的段内级联。
由于客流的高容量和变化,使用基于od的方法估计高峰段站点的负载可能会导致重大误差。然而,由于该路段通常由多条线路提供服务,因此该地区的客流在不同路线上可能表现出相似的空间分布。尽管前往这一路段的乘客来自不同的路线和方向,但他们最终都会到达CBD的共同目的地。为了解决这个问题,我们使用了另一个监督学习模型来直接估计负载,考虑到CBD内站点的坐标和在入站段结束时基于登机的模型估计的负载。前者反映了土地使用的影响,因为相邻站点可能有类似的土地使用类型,而后者反映了服务行程的变化。这样,尽管由于高变化,峰值段中预计会出现错误,但它们不会级联到入站段和出站段的停止。
综上所述,荷载由式14给出
(14)
式中为峰值段采集数据训练的监督学习模型,为第i站坐标,为行程入站段最后一站基于上车方法估计的负荷。
图2显示了基于分段方法的模型框架。
图2
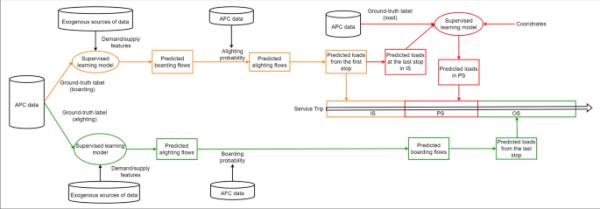
基于分段的模型框架
本节讨论监督学习模型中使用的输入特征。大多数交通模型将变量分为出行需求特征和服务供给特征(Gentile和N?kel 2016)。
需求的特点
旅游需求特征包括基于时间的特征和反映需求分布时空格局的人口普查信息。
基于时间的特征基于时间的特征包括一周中的日期和一天中的时间,这些特征捕捉了客流随时间的变化。
人口普查资料人口普查资料是指对一定人口进行的调查。一些信息,如人口和车辆拥有量,已广泛用于交通需求模型(McNally 2007;Cats 2011)在每个区域生成行程。人口普查数据通常按地理区域汇总,并提供跨空间需求分布的见解。对于第i站,我们选择步行距离内的所有地理区域,并将区域集合表示为。在本研究中,人口普查属性包括居住人口和机动车保有量。
令和表示地理区域a的人口和家庭车辆拥有量。第i站的停车级人口和家庭车辆拥有量为:
(15) (16)
供应特性
服务供给特征反映了根据服务表现分配乘客的情况,包括停留时间和车头时距。这些特征可以从(自动车辆定位)AVL数据中获得,该数据捕获了车辆之间负载分布的可变性。
停留时间停留时间是车辆停留的时间长度。停留时间与上下客总人数有很强的相关性(Sun et al. 2014;Glick and Figliozzi 2017),一些研究使用了停留时间(Bie et al. 2015;Sun et al. 2021)作为乘客需求的代表。第i站行程停留时间计算如下:
(17)
式中为实际出发时间,为行程第I站实际到达时间。
车头时距车头时距是指两个连续的列车到达某一特定站点之间的时间。一个站点的总乘客需求是根据到达的车辆来分配的(Han and Wilson 1982)。假设乘客到站的随机(泊松)过程的研究通常推断在给定站点上车的乘客数量与车头时距成正比(Turnquist 1978;Jenelius 2019)。行程第i站车头时距计算如下:
(18)
式中为本次行程的实际出发时间,表示前一趟到达第i站的实际到达时间。
替代的监督学习模型可用于模型,,,,和“特征开发”中提出的模型框架。在本研究中,我们选择了极限梯度增强(Extreme Gradient boost, XGBoost)模型,因为它在各个领域都被证明是有效的,具有较高的精度和相对较低的计算时间。
XGBoost是一个基于树的模型,它假设数据中的复杂交互可以用树来表示(Chen和Guestrin 2016)。基于树的模型将特征空间划分为一系列矩形,其中每个矩形对应一个简单的模型,通常只是一个常数。XGBoost模型是专门为提高决策树模型的性能而开发的,通过将多个弱预测因子组合在一起,得到一个高度精确的模型和更精确的预测。对于给定的具有m个特征的数据集,XGBoost模型使用K个加性树来创建集成模型:
(19)
式中为回归树空间,q表示将输入映射到相应叶索引的树结构,T为树中叶的个数。每个特征对应一个独立的树结构q和叶权值w。树结构使用树(由q给出)中的决策规则将特征分类到叶中,并通过将相应叶(由w给出)中的权值相加来计算最终预测。模型通过最小化以下损失函数进行训练:
(20)
其中u是衡量预测和目标之间差异的可微凸损失函数,是惩罚回归树复杂性的正则化项。
摘要
介绍
文献综述
方法
案例研究
结果
有限公司
结论及未来工作
参考文献
致谢
作者信息
道德声明
搜索
导航
#####
提出的方法在澳大利亚墨尔本的三条有轨电车路线(11号线、86号线和96号线)上进行了测试。本实验只考虑2020年2月1日至2020年3月16日工作日早高峰(7:00-10:00)从第一站出发,开往中央商务区(CBD)方向的车次。图4(左)显示了这三条电车线路的地理分布。
这三条航线的一部分机队配备了APC系统。使用APC系统记录的客流作为地面真实数据。为了验证APC作为地面真实数据的使用,将APC系统的乘客数据与某些站点授权人员记录的乘客数据进行了比较。获授权的人员会在网络上随机选择的地点登上电车,并在车上停留几站,收集检票数据并估计车上乘客人数。在研究期间,只有数量有限的装有APC装置的车辆停在一些站点。我们从APC数据中发现,11号公路有8趟,86号公路有14趟,这些数据可以与车载调查相匹配。96号公路上的大部分站点没有被检查,导致没有匹配的行程。图3显示了APC在匹配行程的检查站点的平均负载和调查数据。两组数据记录的客运量大致一致,11号线平均偏差为6.18人次,86号线平均偏差为7.19人次。偏差接近所研究车辆(64名乘客)座位容量的10%,表明测量误差在制定运营决策和提供实时拥挤信息方面并不显着。基于这些发现,可以认为原始APC数据与实际观测结果一致,可以作为地面真值数据。经过数据清洗和预处理,得到11号线共161次、44站;86号线共147次、67站;96号线共292次、33站。
图3
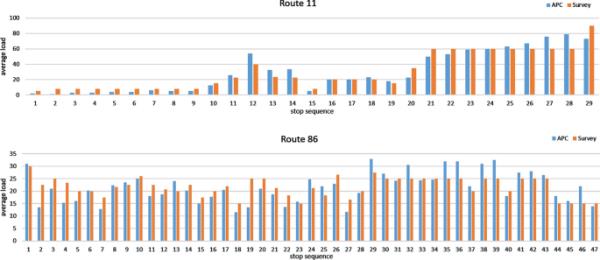
APC记录的11号线和86号线被检查站点的平均客运量和调查数据
Myki是澳大利亚墨尔本用于电子支付票价的AFC系统。它记录单个票价验证轨迹,允许通过行程链估计确定的出发地和目的地对之间的客流量(Nassir et al. 2011, 2015, 2017)。在本研究中,我们采用这些研究提出的基于规则的行程链接程序来处理Myki数据,其中包括上车和下车站点的推断。在研究期间,77.9%的Myki交易地点被成功推断。通过汇总每个服务行程的这些交易,可以推导出乘客负荷。为了解释被破坏的交易,计算了21%的扩展因子。该扩展因子表示确定的事务总数与未确定的事务总数之间的比率。乘客的载客量通过每次行程计算的膨胀系数进行缩放。
图4
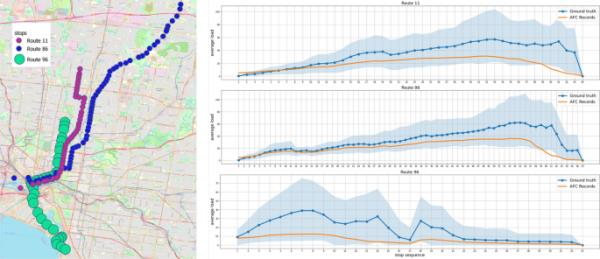
(左)澳大利亚墨尔本11、86、96号公路的地理分布;(右)APC(真值)和AFC数据记录的每站平均负载
图4(右)是研究期间各站APC数据和AFC数据记录的平均客运量的比较。阴影区域表示在APC数据中观察到的变化,以及乘客负荷的百分位数和百分位数。x轴表示停车顺序,y轴表示车上乘客人数。尽管成功地识别了AFC数据中的大多数事务位置并使用扩展因子缩放负载,但我们仍然观察到每个站点的AFC数据记录中存在明显的低估。如前所述,这种差异是由于逃票或免费有轨电车区造成的未记录的旅行。这些缺失信息的分布是不均匀的,因此一个简单的比例因子是不够的。这促使引入监督学习模型来改进乘客负荷的估计。
对于监督学习模型,从“特征开发”中讨论的外生数据源中提取以下输入特征,然后与APC数据匹配。
从澳大利亚统计局获得的人口普查数据是根据澳大利亚统计地理标准定义的统计区域汇总的。估算有轨电车载客量的相关普查数据包括居住人口和车辆拥有量。这些特征是使用公式15 - 16计算的,选择360米的步行距离(从区域质心到车站),这代表了步行到墨尔本电车站的中位数长度(Eady和Burtt 2019)。
自动车辆定位(AVL)数据跟踪每辆车在路线上特定时间点的位置。通用运输馈送规范(GTFS)数据提供了时间表信息,这对于在时间表之间匹配行程是必不可少的。从GTFS数据和AVL数据中,可以得出以下特征:星期几、到达时间和服务供应特征,包括停留时间和车头时距。
对于同程估计问题,使用前两周(2020年2月3日- 2020年2月28日)的数据作为训练集,推导出客流估计模型(,,,,和)。以最近两周的数据作为测试集(02/03/2020-13/03/2020)。
对于交叉路线估计问题,使用其他两条路线的数据作为训练集。例如,为了估计96号线的服务负荷,使用11号线和86号线的APC数据对客流估计模型进行训练。仍然使用相同的测试集作为相同的路线估计问题。
每次服务行程的每一站都转化为一个样本。同路估计和跨路估计所用的样本数量见表1。采用十倍交叉验证方法来调整模型。要确定的参数包括树的深度、树的数量和在树构造过程中列的子样本比。采用网格法选择最优参数。
图5
停止在基于段的模型中使用分割
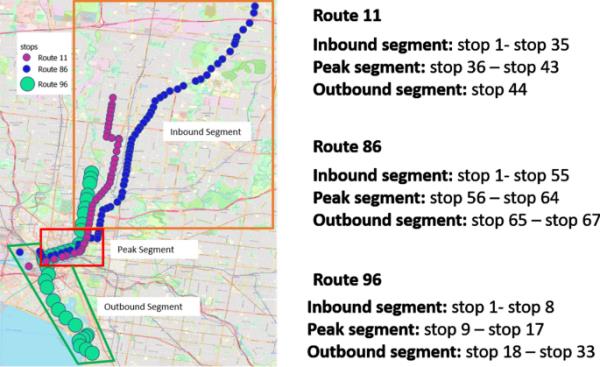
对于基于段的模型(参见“估计框架”),每条路线的站点需要分为三个段:入站段、高峰段和出站段。图5显示了停止分割。入站部分包括北郊的电车站,这是墨尔本的主要住宅区。在早高峰期间,预计许多通勤行程都来自该地区。高峰段与墨尔本中央商务区(CBD)相对应,这里是大多数金融、法律、行政和零售设施的所在地。在早高峰期间,它吸引了各种各样的工人。在墨尔本,值得注意的是,高峰时段与免费服务区重叠,乘客不需要触摸,导致大多数登机流没有被AFC数据记录。出站路段包括码头区、南墨尔本、阿尔伯特公园和圣基尔达。这些郊区以其娱乐设施而闻名,如港口、公园和海滩。虽然它们可能会吸引一些游客,但在工作日的早晨,它们不像CBD那么受欢迎。
表1本研究训练集和测试集的样本数量
使用平均绝对误差(MAE)和均方根误差(RMSE)对估计结果进行评估。N个样本的MAE和RMSE计算如下:
(21) (22)
其中和分别表示样本n的估计客运量和实际客运量。与MAE度量相比,RMSE度量为大误差分配了相对较高的权重。
下载原文档:https://link.springer.com/content/pdf/10.1007/s11116-023-10411-2.pdf

